
- Published on 09 Jan 2018
- External News
The potential of data innovation within manufacturing
Written by Sirris
Manufacturing is an important sector of the European economy. In the last years, thanks to ever-ongoing technological advances in sensor, communication and data storage technologies, this traditional sector has also entered the digital era. To support the manufacturing industry in the process of digital transition, many technological solutions have been developed by different players in the ICT-industry targeting collection, storage and intelligent analysis of industrial data, which is the key enabler for the whole Industry 4.0 revolution. However, the real challenges and opportunities are still not entirely understood since the hype around ‘big data’ and Artificial Intelligence (AI) hampers the wide understanding of the true potential of data science technologies in manufacturing.
Contrary to what most of the success stories in big data applications (typically originating from players like Google, Amazon, etc.) are trying to convince us, the bright future of Industry 4.0 applications will not be realized by simply collecting large amounts of diverse production data and applying intelligent algorithms out of the box, but it will require
- the availability of representative historical data carefully curated by domain expert,
- creativity to derive additional insights about manufacturing processes by linking different data sources, and
- the acquisition of a new technical skillset enabling the identification of the right data-driven business question in a given context.
Data-driven applications to manufacturing
Some examples of data-driven applications to manufacturing are:
- Behaviour quantification. The production performance of a production facility can vary and sometimes deteriorate and evolve very slowly to a suboptimal state. Recordings of regular/abnormal production periods consisting of time series production data and machine logs (as errors, warnings, status updates, alarms) can be used to quantify the production behaviour of a machine/production line in order to detect deviations and potential underperformance.
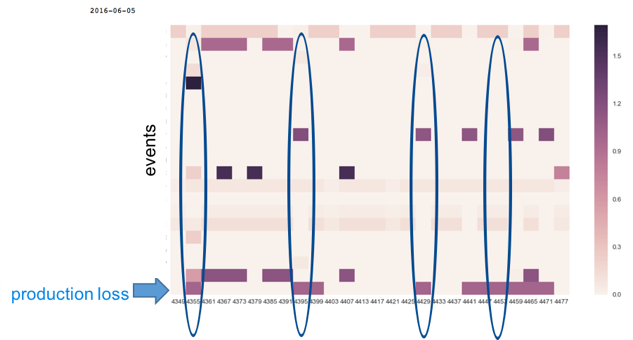
Figure 1: Visual comparison of the frequency of anomalous events across machines to detect deviations in production behaviour
- Optimal configuration. Industrial machines / production lines often need to be configured for a wide range of products. Historical data of stored configurations from several different machines for various different product specifications is usually available and can be used to determine (recommend) the optimal machine (production process) configuration for a given product / production process.

Figure 2: Optimal machine configuration based on similarities in product specifications
- Quality monitoring. Product quality measurements are usually performed once for a certain time window on a sample of products (depending on the process). Time series data of process parameters measurements for each product during production is available and can be used to estimate the product quality parameters based on a subset of the process parameters (This is presently one of the industrial demonstrators being developed by Philips in the Mantis project).
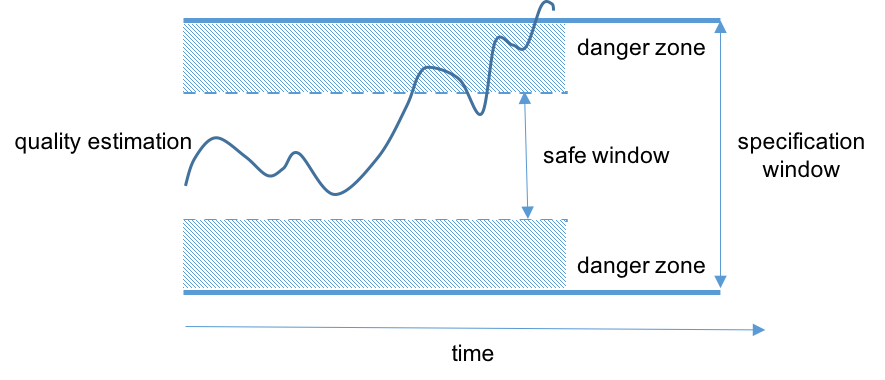
Figure 3: Evolution of the product quality within a particular quality specification window
Having access to the right data and the right knowledge
In any of the above cases, applying an intelligent algorithm to the available data as such will not directly produce exploitable results. Even the most intelligent algorithm will be useless without some prior knowledge of the application domain and the right data to analyse. Gaining an understanding of a certain phenomenon, e.g. underperformance, and identifying the factors that cause it requires exploring and analysing the available (historical) data. A data scientist / domain expert needs to investigate many different (non-integrated) datasets: sensor data, event logs, environmental conditions, maintenance records, configuration documentation, etc. This process typically involves the following steps: 1) identify and gather a representative sample dataset (since the complete dataset might either be too big to explore or too hard to collect) 2) analyse the (representative sample) data in a systematic way to find interesting structures, patterns, correlations, regularities, ... 3) combine domain knowledge with data-driven insights to gain understanding into the mechanisms of failures, anomalies and performance degradation and 4) formulate a working hypothesis. Subsequently, most of the different data exploration steps are executed either manually or in an ad-hoc, non-reproducible and often not fully correct fashion. However, the implementation feasibility and the performance of any AI solution is strongly conditioned by the efficiency and correctness of the preceding data exploration phase.
Challenges related to (industrial) data
A typical problem with industrial data is the lack of ground truth, i.e. the data itself does not explicitly document which production cycles are considered as normal, or which set of configuration parameters contribute to improved production performance. This is one of the most common and underestimated challenges related to the application of advanced AI technologies to industrial contexts. Some other challenges are:
- the lack of data standardization, meaning that each asset might report and log operational data in a different and potentially incompatible format,
- the poor data quality and representativeness, i.e. real-world data contains missing values, outliers and noise,
- the redundancy of the data versus its relevance: an industrial asset can sometimes report more than 1000 warnings, alarms, statuses, failures, … per day during several weeks,
- the lack of sufficient domain knowledge: there are many influencing factors to take into account e.g. environmental conditions, which are not always known, and
- finally, as different datasets might be captured in different time zones, with different sampling intervals, covering different time periods, the datasets should be synchronized timewise, which is however sometimes just not possible.
Data ownership and data sharing across complex value chains
Ownership of data across the value chain of industry 4.0 applications might be very complicated. It is therefore an essential question that needs to be clarified even before considering to explore the added value of data-driven services. Does a company selling a set of industrial machines to its customers own the data or are the customers allowed to have a full control of the data produced by their machines? The answer is that it depends on the context and on the relationship between the different players in the value chain that have sometimes evolved historically .
If the customer owns the data generated by their assets, then they are typically not very eager to grant data access to the original asset manufacturer. They often fear data analysis will reveal issues with asset usage, which might impact guarantee and maintenance agreements. In other industrial contexts, the asset manufacturers are invoking their IP rights in order to shield a large proportion of the data from the asset owner, fearing that the analysis of such data might be used for reverse engineering. The revenues generated thanks to the additional services those manufacturers can offer due to the data are not negligible though.
There is no doubt that data sharing across the value chain is essential for realizing Industry 4.0. However, data sharing and ownership is not clearly regulated and it are typically the large players who are able to benefit from the present situation.
The role of the human
To conclude, data by itself does not provide the answer to everything. Data science is a trial-and-error process and the human factor will always be an important element in the data innovation process. Not everything can be automated and common sense is needed to verify and validate results. Data and algorithms are only useful as long as a human decision is behind it. Finally, it is a team effort as data innovation requires a unique combination of knowledge and skills (e.g. domain knowledge, creativity, analytical thinking, statistics and machine learning, programming and visualization), and a complementary team of people, because all this knowledge and skills are rarely found in a single person.
Sirris EluciDATA Innovation Lab
Sirris is a private collective research center founded in 1949 by Agoria, the multi-sector federation for the Belgian technology industry. Sirris' mission is to improve the competitiveness of its member companies through technology and innovation in 5 domains of expertise: ICT, advanced manufacturing, mechatronics, materials and sustainability. Within Sirris, the expertise with relation to advanced data processing is bundled in the EluciDATA Innovation Lab. It is composed of highly qualified experts who support Belgian companies to formulate their data sciences task. We initiated and participated in several industry-driven research programs through which we have acquired extensive knowledge in various areas related to topics such as predictive analytics, complex event processing, proactive and context-sensitive decision support, entity profiling and modelling and have developed industrial demonstrators:
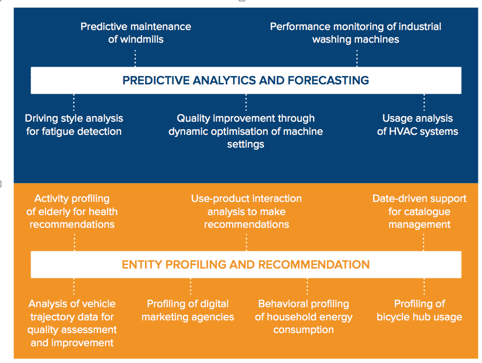
For further information on the Sirris EluciDATA Innovation Lab and Sirris: http://www.elucidata.be and http://www.sirris.be (contact: Elena Tsiporkova, Program Manager Data Innovation: elena.tsiporkova@sirris.be)